반응형
'Stéphane Maarek - Kafka Streams'를 보고 작성한 글입니다. 😀
1. build.gradle 설정
plugins {
id 'java'
}
group 'hardenkim.github.io'
version '1.0'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine'
compile group: 'org.apache.kafka', name: 'kafka-streams', version: '2.7.0'
compile group: 'org.slf4j', name: 'slf4j-simple', version: '1.7.30'
compile group: 'com.google.code.gson', name: 'gson', version: '2.8.5'
}
test {
useJUnitPlatform()
}2. Stream 코드
public class WordCount {
static final String inputTopic = "streams-plaintext-input";
static final String outputTopic = "streams-wordcount-output";
static final String bootstrapServers = "localhost:9092";
public static void main(String[] args) {
final Properties streamsConfiguration = getStreamsConfiguration(bootstrapServers);
final StreamsBuilder builder = new StreamsBuilder();
createWordCountStream(builder);
final KafkaStreams streams = new KafkaStreams(builder.build(), streamsConfiguration);
// 이전에 로컬 상태를 정리할 때의 단점은 앱이 처음부터 로컬 상태를 다시 빌드해야한다.
// 이 경우 시간이 걸리고 네트워크를 통해 Kafka 클러스터에서 모든 상태 관련 데이터를 읽어야한다.
// 따라서 프로덕션 시나리오에서는 일반적으로 여기에서하는 것처럼 항상 정리하는 것이 아니라 실제로 필요할 때만,
// 즉 특정 조건(예 : 앱에 대한 명령 줄 플래그가있는 경우)에서만 사용한다.
streams.cleanUp();
streams.start();
// shutdown hook -> application 옳바르게 종료
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
// 5초 마다 토폴로지 출력 (잘되는지 확인..ㅎ)
while(true){
streams.localThreadsMetadata().forEach(data -> System.out.println(data));
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
break;
}
}
}
static Properties getStreamsConfiguration(final String bootstrapSerers){
final Properties streamsConfiguration = new Properties();
// Streams 애플리케이션에 ID 지정 (ID는 애플리케이션이 실행되는 Kafka 클러스터에서 중복되면 안된다)
streamsConfiguration.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-example");
streamsConfiguration.put(StreamsConfig.CLIENT_ID_CONFIG, "wordcount-example-client");
// kafka 브로커 주소
streamsConfiguration.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// offset 처음부
streamsConfiguration.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// key, value 직렬화 및 비직렬화 / 데이터를 어떠한 형식으로 read/write 할지 설정
streamsConfiguration.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
streamsConfiguration.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// 예제이므로 캐쉬 비활성화
streamsConfiguration.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0);
return streamsConfiguration;
}
static void createWordCountStream(final StreamsBuilder builder){
final KStream<String, String> textLines = builder.stream(inputTopic);
final KTable<String, Long> wordCounts = textLines
// 공백으로 split / 소문자로 변경
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// 텍스트 단어를 메시지 키로 그룹화
.groupBy((key, value) -> value)
// 단어 카운트
.count();
// output topic에 KTable 작성
wordCounts.toStream().to(outputTopic, Produced.with(Serdes.String(), Serdes.Long()));
}
}3. Kafka 토픽 생성
input topic
kafka-topics.sh --create --topic streams-plaintext-input --zookeeper localhost:2181 --partitions 1 --replication-factor 1output topic
kafka-topics.sh --create --topic streams-wordcount-output --zookeeper localhost:2181 --partitions 1 --replication-factor 1

4. producer 및 consumer 실행
# producer
kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
# producer에 데이터 삽입
> hi my name is harden
> hi my name is bob
...

# consumer
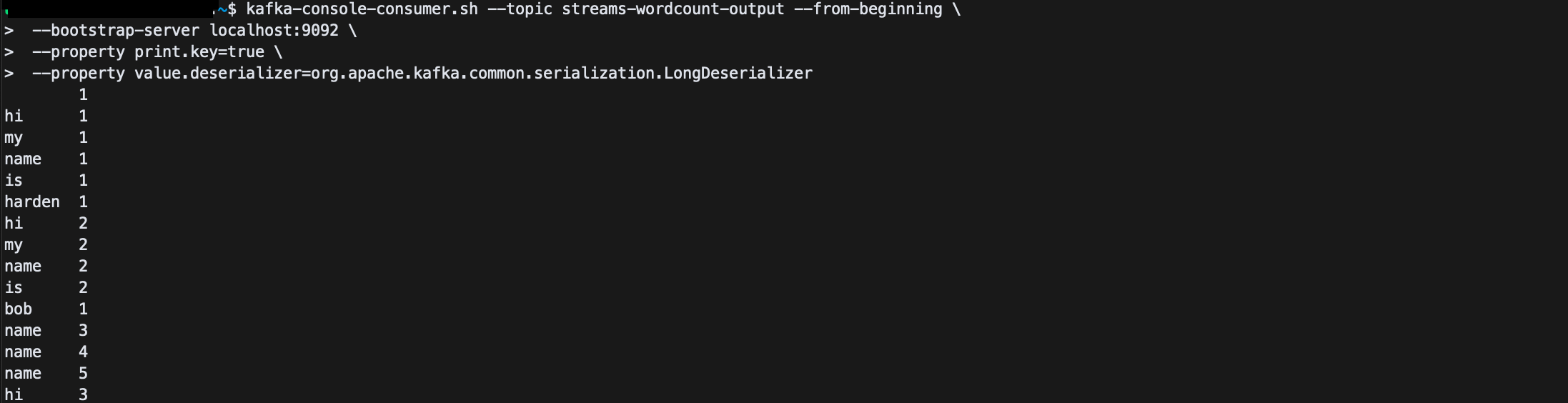
kafka-console-consumer.sh --topic streams-wordcount-output --from-beginning \
--bootstrap-server localhost:9092 \
--property print.key=true \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
References
🏋🏻 개인적으로 공부한 내용을 기록하고 있습니다.
잘못된 부분이 있다면 과감하게 지적해주세요!! 🏋반응형
'Kafka' 카테고리의 다른 글
| [Kafka] Kafka Stream 에제 3 - bank-balance-exactly-once (0) | 2021.11.23 |
|---|---|
| [Kafka] Kafka Stream 에제 2 - FavoriteColor (0) | 2021.11.23 |
| [Kafka] Ubuntu(우분투)에 Kafka 설치 및 실행 (EC2) (0) | 2021.11.23 |




댓글