'Stéphane Maarek - Learn Apache Kafka for Beginners v2'를 보고 작성한 글입니다. 😀
1. Twitter APPs
Twitter Apps 에서 회원가입을 하고 간단한 앱을 만들어 key랑 token을 받는다

2. Producer with Twitter API
Twitter API를 통해 원하는 tweet을 kafka로 가져와야한다. 이번 예제에서 사용할 API는 twitter java api를 이용한다
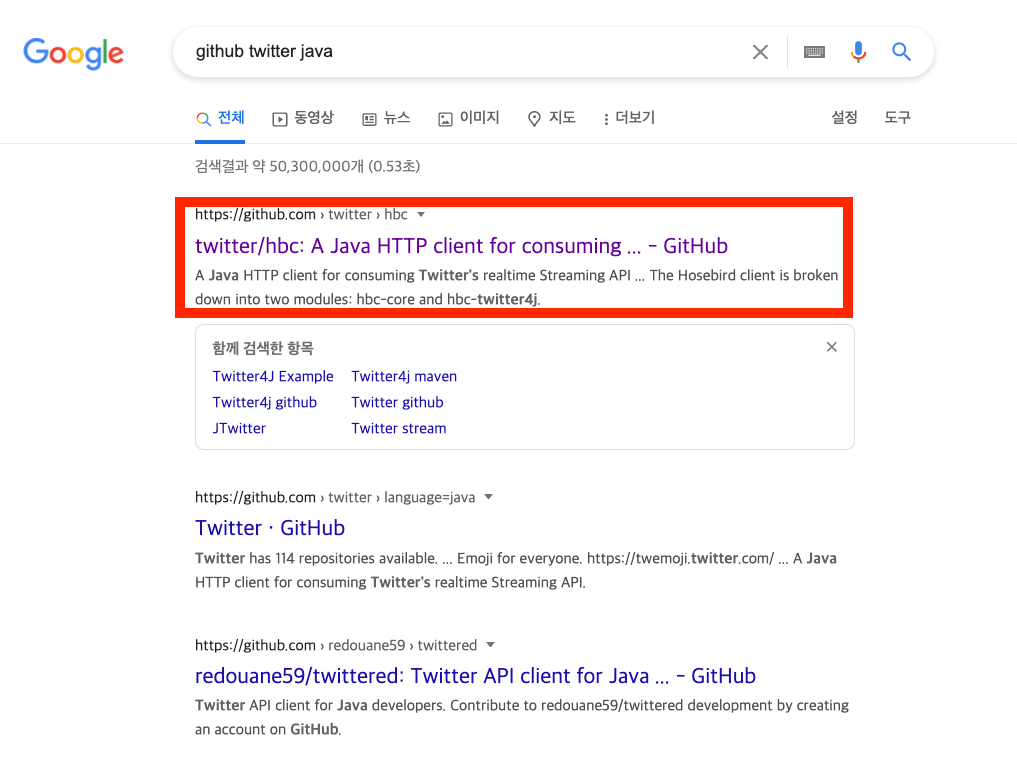
github를 들어가보면 Quickstart를 통해 쉽게 사용이 가능하다
3. Twitter Producer
Kafka Producer와 Twitter API를 사용하기 위해 build.gradle에 dependency를 추가한다
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine'
compile group: 'org.apache.kafka', name: 'kafka-clients', version: '2.7.0' // Kafka
compile group: 'com.twitter', name: 'hbc-core', version: '2.2.0' // Twitter API
compile group: 'org.slf4j', name: 'slf4j-simple', version: '1.7.30' // slf4j logger
}
Twitter API client 설정
/* Twitter API client */
public Client crateTwitterClient(BlockingQueue<String> msgQueue){
/** Declare the host you want to connect to, the endpoint, and authentication (basic auth or oauth) */
Hosts hosebirdHosts = new HttpHosts(Constants.STREAM_HOST);
StatusesFilterEndpoint hosebirdEndpoint = new StatusesFilterEndpoint();
// 원하는 tweet 키워드
List<String> terms = Lists.newArrayList("bitcoin", "TESLA", "SAMSUNG", "NASDAQ", "KOSPI");
hosebirdEndpoint.trackTerms(terms);
String consumerKey = "your consumerKey";
String consumerSecret = "your consumerSecret";
String token = "your token";
String secret = "your secret";
// Twitter APPs 에서 얻은 key와 token
Authentication hosebirdAuth = new OAuth1(consumerKey, consumerSecret, token, secret);
ClientBuilder builder = new ClientBuilder()
.name("Hosebird-Client-01") // log를 위한 옵션
.hosts(hosebirdHosts)
.authentication(hosebirdAuth)
.endpoint(hosebirdEndpoint)
.processor(new StringDelimitedProcessor(msgQueue));
// Client
Client hosebirdClient = builder.build();
return hosebirdClient;
}
Producer의 Configuration 설정
/* Producer Config */
public KafkaProducer<String, String> createKafkaProducer(){
// Propertites
Properties properties = new Properties();
// bootstrapserver (예: localhost:9092)
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
//KEY_SERIALIZER_CLASS_CONFIG 직렬화
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// VALUE_SERIALIZER_CLASS_CONFIG 직렬화
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 멱등성 보장 (중복방지)
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
// 데이터 유실 방지
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// 재시도 횟수
properties.put(ProducerConfig.RETRIES_CONFIG, Integer.toString(Integer.MAX_VALUE));
// 한번에 5개 보내기 -> 데이터 순서가 바뀔 수 있음
properties.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "5");
// 대역폭 향상 -> 약간의 지연 및 cpu 점유율 증가
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
// 배치 대기 시간
properties.put(ProducerConfig.LINGER_MS_CONFIG, "20");
// 배치 사이즈
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32*1024)); // 32KB batch size
// Producer
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
return producer;
}
Twitter API Client로 tweet을 얻고 Kafka에 전송하기
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(TwitterProducer.class.getName());
logger.info("Setup");
/** Set up your blocking queues: Be sure to size these properly based on expected TPS of your stream */
BlockingQueue<String> msgQueue = new LinkedBlockingQueue<String>(1000);
// twitter client 생성h
Client client = crateTwitterClient(msgQueue);
// 연결
client.connect();
// kafka producer 생성
KafkaProducer<String, String> producer = createKafkaProducer();
// shutdown hook 추가
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
logger.info("stopping application...");
logger.info("shutting down twitter client...");
client.stop();
logger.info("closing kafka producer...");
producer.close();
logger.info("done!");
}));
// kafka topic에 tweet 전송하기
while (!client.isDone()) {
String msg = null;
try {
// tweet 가져오기
msg = msgQueue.poll(5, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
client.stop();
}
if (msg != null) {
logger.info(msg);
// topic에 tweet 전송하기
producer.send(new ProducerRecord<>("twitter_tweets", null, msg), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null){
logger.error("Something bad happened", e);
}
}
});
}
}
logger.info("End of application");
}
4. ElasticSearch Consumer
Kafka Consumer와 ElasticSearch를 사용하기 위해 build.gradle에 dependency를 추가한다
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine'
compile group: 'org.apache.kafka', name: 'kafka-clients', version: '2.7.0' // Kafka
compile group: 'org.elasticsearch.client', name: 'elasticsearch-rest-high-level-client', version: '7.11.2' // ElasticSearch
compile group: 'com.google.code.gson', name: 'gson', version: '2.8.5' // JsonParser
compile group: 'org.slf4j', name: 'slf4j-simple', version: '1.7.30' // slf4j logger
}
ElasticSearch API client 설정
/* ElasticSearch Connect */
public static RestHighLevelClient createClient() {
String hostname = "your hostname";
String username = "your username";
String password = "your password";
// local 이 아닌 Cloud ElasticSearch에에 접속할 때 사용
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(username, password));
RestClientBuilder builder = RestClient.builder(
new HttpHost(hostname, 443, "https")) // port 443 for https
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {
return httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
});
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
Consumer의 Configuration 설정
/* Consumer Config */
private static String GROUP_ID = "kafka-demo-elasticsearch";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
public static KafkaConsumer<String, String> createConsumer(String topic){
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// auto commit 사용 x
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// poll 당 최대 record 100개
properties.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "100");
// Consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList(topic));
return consumer;
}
Consumer로 tweet을 받고 ElasticSearch에 전송하기
- at least once 를 사용하여 tweet이 ElasticSearc에 중복으로 전송될 경우 id를 통해 reinsert 하여 중복을 방지
// gson 의 JSonParser() 를 통해 json 사용
private static JsonParser jsonParser = new JsonParser();
// tweet ID 추출 (중복 방지)
private static String extractIdFromTweet(String tweetJson){
// gson library
return jsonParser.parse(tweetJson)
.getAsJsonObject()
.get("id_str")
.getAsString();
}
public static void main(String[] args) throws IOException {
Logger logger = LoggerFactory.getLogger(ElasticSearchConsumer.class.getName());
RestHighLevelClient client = createClient();
// Consumer 생성
KafkaConsumer<String , String> consumer = createConsumer("twitter_tweets");
// 새로운 데이터 poll
while(true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
Integer recordCount = records.count();
logger.info("Received " + recordCount + " records");
// 여러개 한번에 묶어서 request
BulkRequest bulkRequest = new BulkRequest();
for (ConsumerRecord<String, String> record : records){
try {
String id = extractIdFromTweet(record.value());
// indexRequest
IndexRequest indexRequest = new IndexRequest("twitter")
.source(record.value(), XContentType.JSON)
.id(id); // 중복일 경우 reinsert를 위해 id 추가
bulkRequest.add(indexRequest); //bulk request 에 추가
} catch (NullPointerException e){
logger.warn("skipping bad data: " + record.value());
}
// ElasticSearch에 tweet 전송
if (recordCount > 0) {
BulkResponse bulkItemResponses = client.bulk(bulkRequest, RequestOptions.DEFAULT);
logger.info("Committing offsets...");
consumer.commitSync(); // auto commit을 하지 않았기 때문에 데이터 전송 후 commit
logger.info("Offsets have been committed");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
5. Twitter Consumer 실행
Topic 생성
# input topic
kafka-topics.sh --zookeeper localhost:2181 --create --topic twitter_tweets --partitions 3 --replication-factor 1
Producer 실행
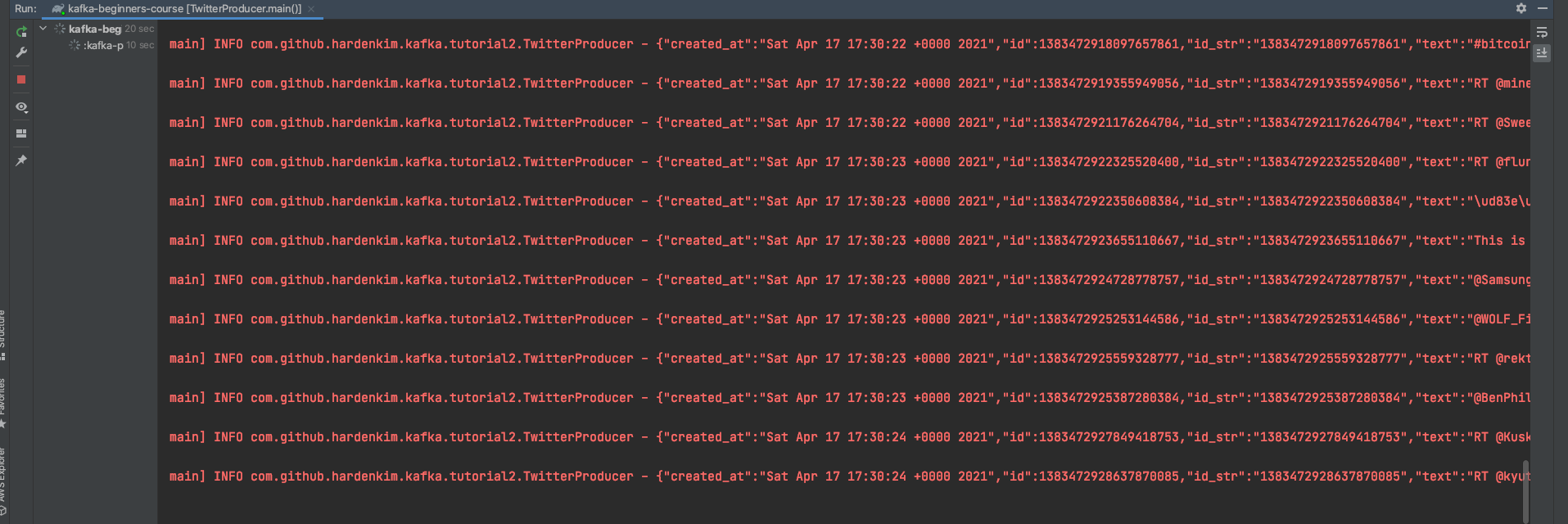
Consumer 실행
# consumer
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic twitter_tweets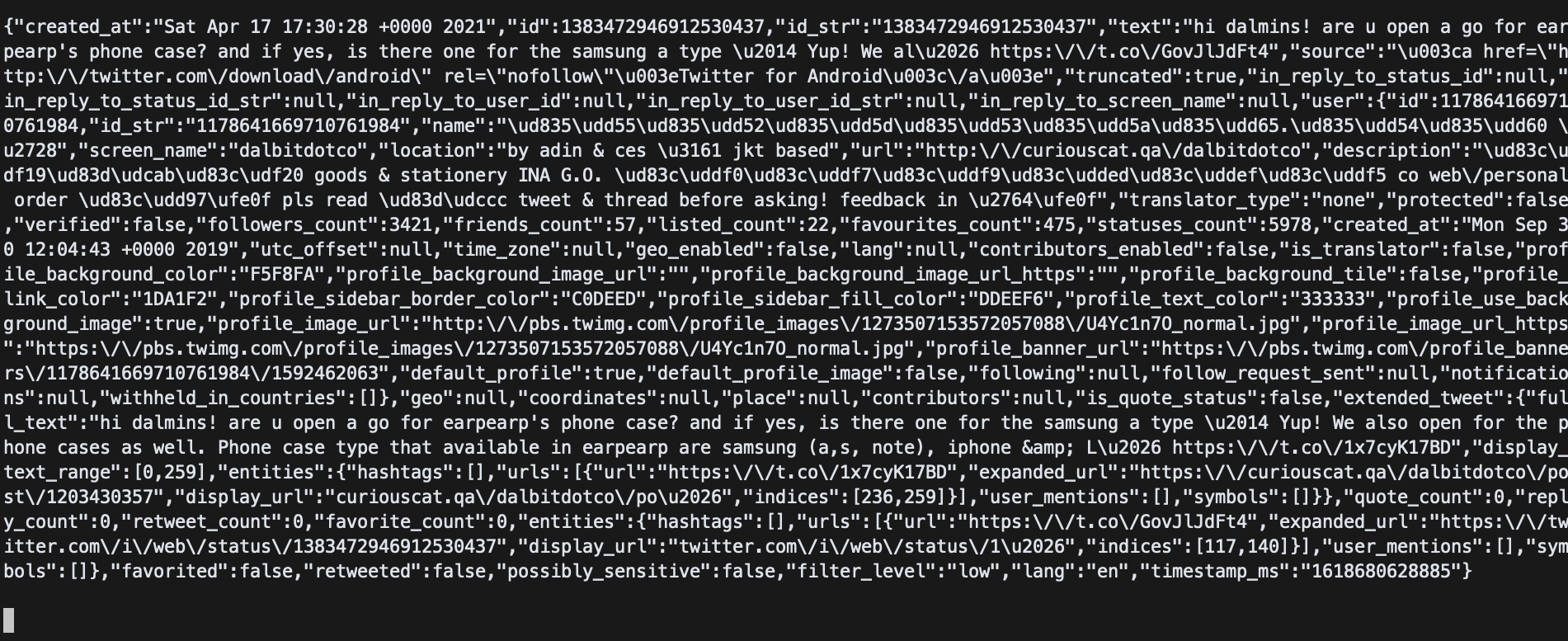
위의 그림과 같이 tweet이 topic에 잘 들어온다
6. ElasticSearch Consumer 실행
Consumer 실행

ElasticSearch 확인
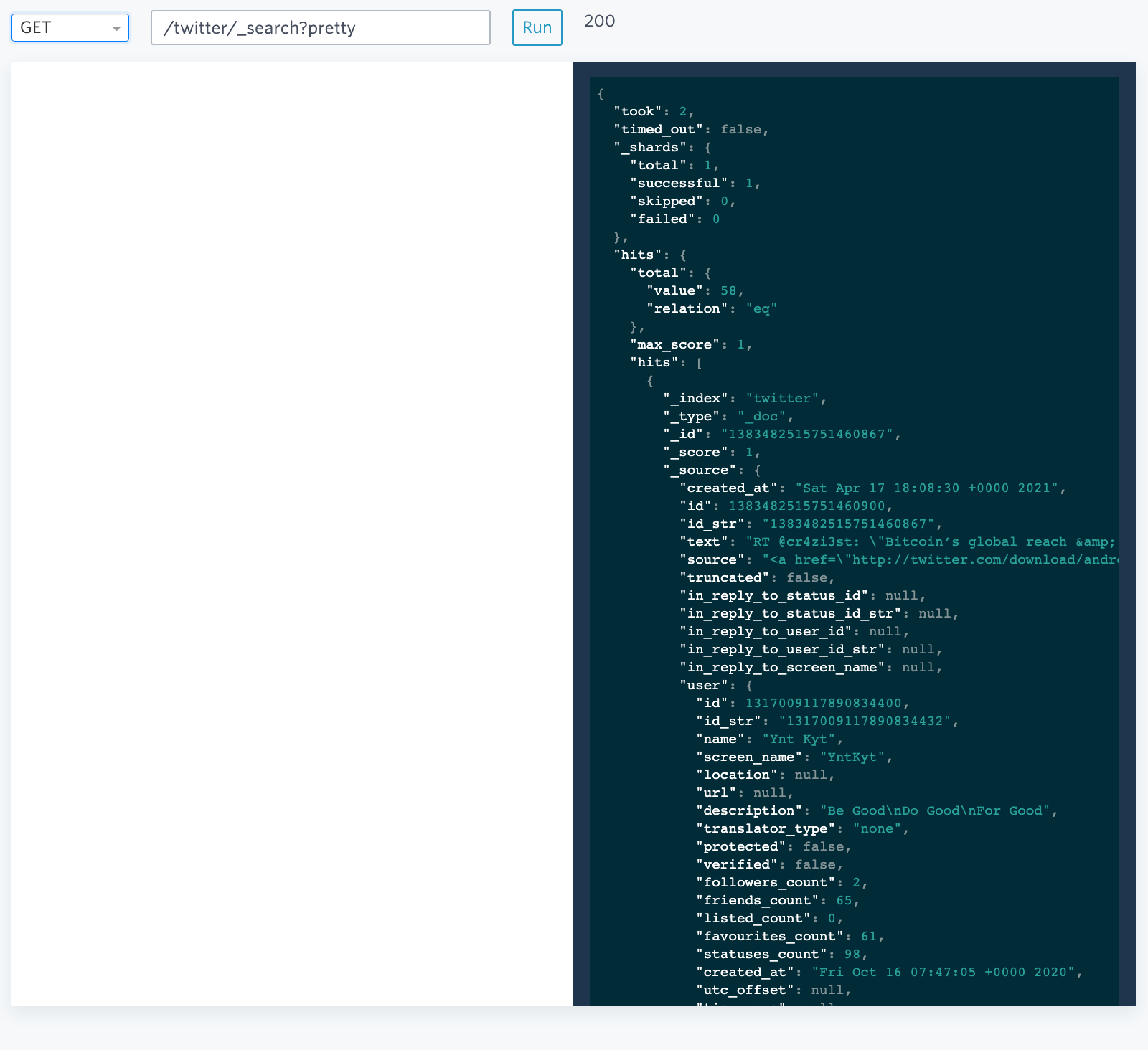
위의 그림과 같이 ElasticSearch로 데이터가 잘 들어오는 것을 볼 수 있다
7. Stream (번외)
간단하게 stream을 이용해 위의 "twitter_tweets" Topic에서 팔로워 수가 1000명 이상인 경우만 따로 topic에 저장해보자
Kafka stream과 Json을 위해 google의 gson을 build.gradle에 dependency를 추가한다
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine'
compile group: 'org.apache.kafka', name: 'kafka-streams', version: '2.7.0' // Kafka-Stream
compile group: 'com.google.code.gson', name: 'gson', version: '2.8.5' // JsonParser
compile group: 'org.slf4j', name: 'slf4j-simple', version: '1.7.30' // slf4j logger
}
StreamBuilder를 통해 이전 twitter Topic애서 필터링 후 새로운 Topic으로 데이터 전송
public class StreamsFilterTweets {
private static String TOPIC_NAME = "twitter_tweets";
private static String APPLICATION_ID = "demo-kafka-streams";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
// Configurations
Properties properties = new Properties();
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_ID);
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.StringSerde.class.getName());
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.StringSerde.class.getName());
// create a topology
StreamsBuilder streamsBuilder = new StreamsBuilder();
// 이전 twitter Topic
KStream<String, String> inputTopic = streamsBuilder.stream(TOPIC_NAME);
// .filter() 메소드를 통해 필터링
KStream<String, String> filteredStream = inputTopic.filter(
// 팔로워 1000명 넘는 tweet 필터링
((key, jsonTweet) -> extractUserFollowersInTweet(jsonTweet) > 1000)
);
// 새로운 'important_tweets' Topic 에 데이터 전송
filteredStream.to("important_tweets");
// build the topology
KafkaStreams kafkaStreams = new KafkaStreams(
streamsBuilder.build(),
properties
);
// Stream 시작
kafkaStreams.start();
}
private static JsonParser jsonParser = new JsonParser();
private static Integer extractUserFollowersInTweet(String tweetJson){
// gson 라이브러리
try {
return jsonParser.parse(tweetJson)
.getAsJsonObject()
.get("user")
.getAsJsonObject()
.get("followers_count")
.getAsInt();
}
catch (NullPointerException e){
return 0;
}
}
}
Topic 생성
# output topic
kafka-topics.sh --zookeeper localhost:2181 --create --topic important_tweets --partitions 3 --replication-factor 1
consumer 실행
# consumer
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic important_tweets

followers_count 값이 모두 1000이 넘는 것을 볼 수 있다
References
🏋🏻 개인적으로 공부한 내용을 기록하고 있습니다.
잘못된 부분이 있다면 과감하게 지적해주세요!! 🏋'Kafka' 카테고리의 다른 글
| [Kafka] 카프카 커맨드 라인 툴 (command-line tool) (0) | 2021.11.23 |
|---|---|
| [Kafka] Advanced Topic Configurations (0) | 2021.11.23 |
| [Kafka] Partitions Count, Replication Factor (0) | 2021.11.23 |




댓글